Most systems have no problems growing their data volume through their APIs once they acquired users. But until then, especially in development and testing it is very helpful to have some tools available to load data, e.g. from JSON or CSV files. Especially in new projects where you don’t have existing databases and backends that are already filled to the brim with existing data. Of course you can use your existing tooling for populating your databases, but how much fun is that?
I faced the same challeng when working on our own GraphQL backend. I had a nice schema, with queries and mutations, but no data served. Initially I entered a bit of data through the mutations in GraphiQL. The ability to use multiple mutations in the same request comes in quite handy.
mutation createData {
fg: createMovie(id: "11", title:"Forrest Gump", year:1994)
ap: createMovie(id: "13", title:"Apollo 13", year:1995)
th: createActor(id: "121", name:"Tom Hanks", born: 1956)
kb: createActor(id: "6", name:"Kevin Bacon", born: 1958)
fgActors: addMovieActors(id: "11", movies:["121"])
apActors: addMovieActors(id: "13", movies:["121","6"])
}I really wanted to have a tool that allows me to drive data loading through these mutations, also to demonstrate that they work and perform well.
Having worked with and liking graphcool’s graphql-cli tools, I felt this would be a nice addition as a plugin.
TL;DR: Usage instructions
If you’re not interested in the nitty gritty details, here is how you get started with graphql-cli-load
npm install -g graphql-cli graphql-cli-load
# configure your graphql endpoint (don't forget to https://medium.com/@mesirii/first-steps-with-graphcools-graphql-command-line-tools-3aa137271420[add auth-headers as needed])
graphql init
graphql ping
graphql get-schema
# load data
graphql load -m createMovie --json movies.json
graphql load -m createActor --json people.json
graphql load -m addMovieActors --csv actors.csv --mapping '{"movieId":"id"}' --delim ','
Here is our minimal GraphQL schema.
type Movie {
id: ID!
title: String
year: Int
actors: [Actor] @relation(name: "ACTED_IN", direction: IN)
}
type Actor {
id: ID!
name: String
}graphql load [--json=file.json] [--csv=file.csv] [--endpoint=name] [--mutation=createType] [--mapping='{"title":"name"}']
Optionen:
--help show help
--mapping, -p name mapping of input to mutation (json)
--mutation, -m mutation to call
--endpoint, -e endpoint name to use
--json, -j json file to load
--csv, -c csv file to load
Introducing: graphql-cli-load
The goal for this plugin is to feed existing mutations with data from CSV or JSON files with the following features:
-
utilize schema provided by graphql-config
-
determine existing mutations, allow the user to select one
-
read existing CSV and JSON files
-
map input data (column-, key-names) to the input arguments of the mutation
-
execute mutations in batches, e.g. 100 at a time until the whole file is processed
The biggest challenge for me was that I wrote this plugin on the plane without internet access, that made finding the relevant APIs a bit tricky, and mostly consisted of looking at the sources.
How does it work?
-
First of all, I have to integrate with graphql-cli and esp. graphql-config to get access to the configuration and schema file.
-
With that I can use the AST parser from graphql.js to parse the schema to get access to all mutations.
-
Then I check the data files, CSV files are loaded via PapaParse and JSON files currently via
fsand JSON.parse (that can def. be improved). -
At last we iterate over the loaded data and create and execute batches of mutation calls (currently 100)
Obligatory Example: The movie database
I quickly spin up the default movie database with neo4j-graphql-cli to demonstrate the loader.
[
{
"id": 0,
"title": "The Matrix",
"year": 1999
},
{
"id": 11,
"title": "The Devil's Advocate",
"year": 1997
}
...
[
{
"id": 4,
"name": "Hugo Weaving"
},
{
"id": 2,
"name": "Carrie-Anne Moss"
}
...
movieId,actors 56,"57,22,60,59,58" 29,"34,33,30,16,32,31" ...
npm install -g neo4j-graphql graphql-cli graphql-cli-load
mkdir movies; cd movies
graphql init
neo4j-graphql movies-schema.graphql
graphql fetch-schema
grep -e "\(create\|add\)" schema.graphql
# addMovieActors(id: ID!, actors: [ID!]!): String
# createMovie(id: ID!, title: String, year: Long): String
# createActor(id: ID!, name: String): String
graphql load -m createMovie -file movies.json
graphql load -m createPerson -file people.json
graphql load -m addMovieActors -file actors.csv -mapping '{movieId:movie, roleName: role}'
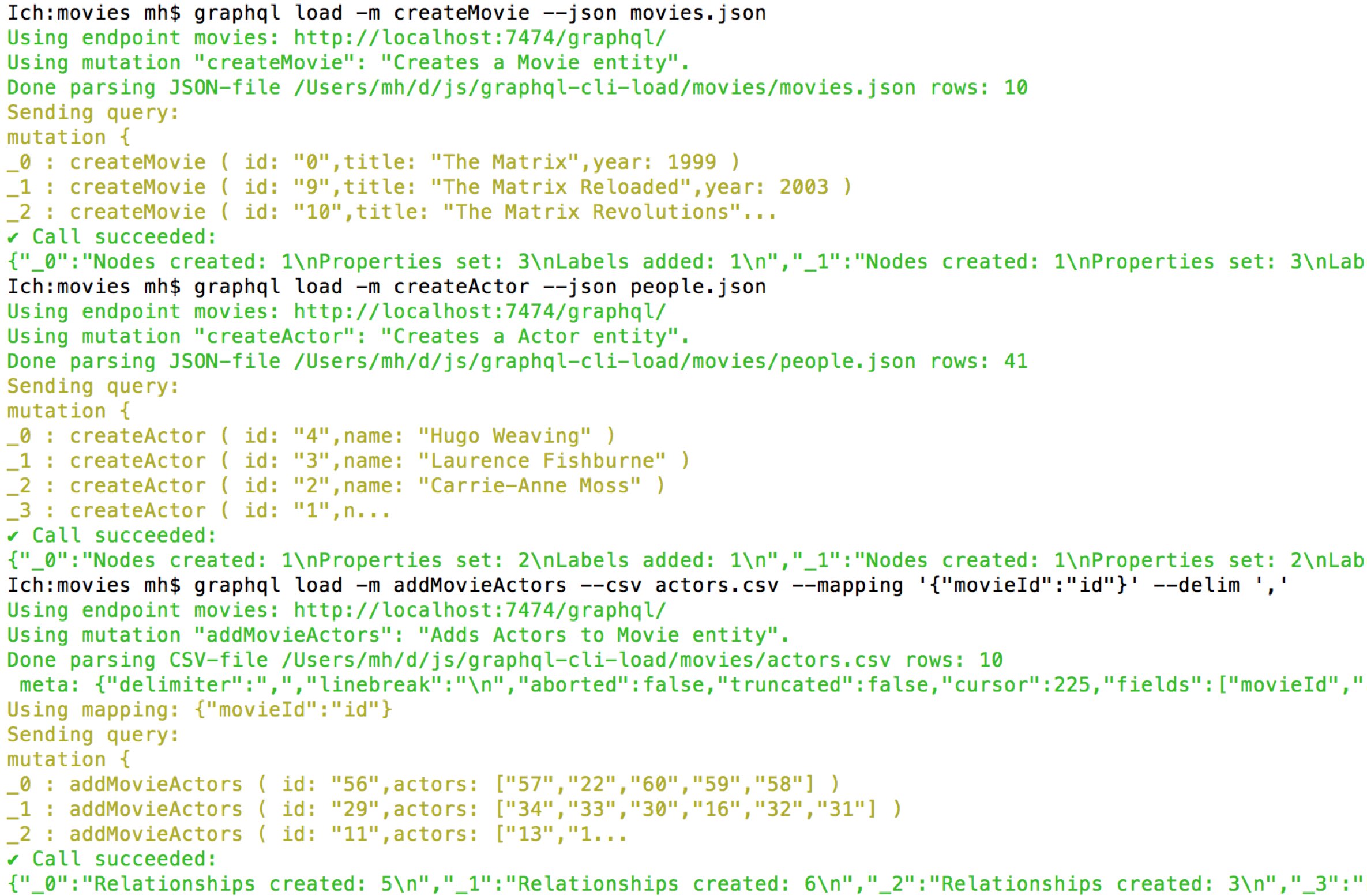
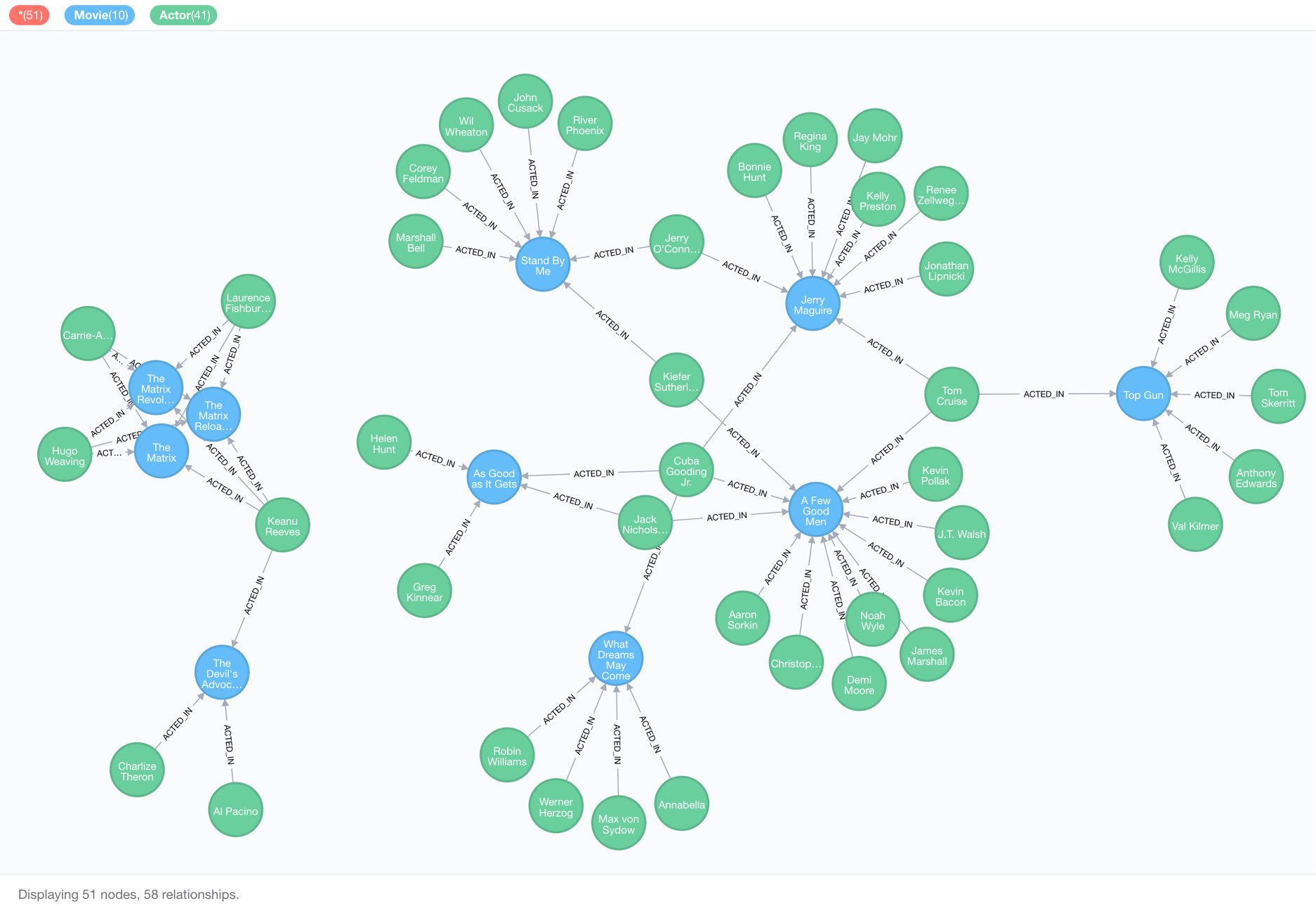
And voila, if we look into our database, we see it populated with our example data:
Please give it a try
As it is often the case building such a tool is about scratching your own itch. But I really think and hope that the tool is useful for you too.
So, please give it a try and let me know what you think in the comments. Even better, help improve it, by creating an issue or sending a pull request to the repository.
Planned improvements
-
I want to be able to run multiple mutations and files in a single call.
-
Supporting http(s) sources for the files should be easy
-
It could also be helpful, instead of calling the APIs to just generate the GraphQL files.
-
Supporting streaming JSON would be nice too.
-
I also want to support GraphQL parameters, esp. to avoid injections and improve performance, but have to figure out how to do it well with the batched mutations
-
Other file formats like XML, YAML or even pulling from source databases would be useful too.
-
Better data conversion to the expected data types of the mutation arguments.
What else are YOU missing?